第9章 函数
罗杰:对我来说,99%的事情都能由R完成。但是让人郁闷的是,当我需要订个披萨饼时,我还是得抓起电话。
道格:美国很多披萨饼连锁店提供网上预订服务啊。R有互联网模块,所以,披萨预订函数的出现只是个早晚问题。— June 2004
终于轮到介绍 R 的精髓了,那就是包包。“包治百病”,R里面有成千上万个漂亮包包,可以帮我们解决所有问题。——女同胞请先收敛一下两眼放出的光芒。R的包是扩展包25,package。
欲知扩展包,必先知函数,function。
9.1 内置函数:全自动厨师机
到现在为止,我们已经遇到过很多函数了。一个函数就像一台全自动厨师机。我们输入一些原材料,然后按个按钮让它运转,叮!它就输出来一盘好菜。
比如,假定世界上有一台专门做番茄炒蛋的自动厨师机,那么我们用R语言来写使用说明书,就是这样的:
x <- 番茄炒蛋机(番茄 = 3个,鸡蛋 = 2个,盐 = 2勺, 油 = 2勺)运行一下,一份美味的番茄炒蛋就放在名叫x的这个盘子里,送到了我们的眼前。圆括号里是我们指定的配方;如果我们没有指定,那么R就按他自己认为的默认配方来做。
对比一下前面我们学过的函数就会发现,他们确实都是这样的厨师机:
x1 <- mean(x = 1:3)
x2 <- read.csv(file = "c:/r4r/co2.csv")R其实就是由不同功能的自动厨师机拼成的一个大厨房,有的厨师机独立工作,但大部分厨师机是相互协作的,一台厨师机输出的半成品或成品,会接着输入到另一台厨师机继续加工,直到把我们点的菜做好。比如我们运行了一个叫做“可乐鸡翅”的函数,输入的是水、香精、鸡翅等,那么R就会先召唤“可乐饮料机”函数做出可乐,再和鸡翅等原材料一起做可乐鸡翅。这就是函数之间的调用。
我们以前用过的,都是 R 基础安装包里一些预先设置好的函数。比如:
y <- sd(x = 1:5) # sd 是函数名, x 是自变量。
y## [1] 1.581139sd()这台厨师机,输入的原料是个数值型向量,输出的菜是标准差。当我们点了sd()这道菜后,R 在厨房里到底忙活个啥呢?输入函数名并回车,或者光标移到函数名上按F2快捷键,就能看到烹饪方法了:
sd## function (x, na.rm = FALSE)
## sqrt(var(if (is.vector(x) || is.factor(x)) x else as.double(x),
## na.rm = na.rm))
## <bytecode: 0x000000000da55a00>
## <environment: namespace:stats>从这个烹饪方法的第二行可以看到,计算方法是先对输入的原材料x进行初步加工(检查和转换格式),再用var()函数求方差,最后开平方。
甚至像 x <- 1:5 这一句,其实背后运行的也是个函数,等同于:
assign("x", 1:5)9.2 自定义函数:自制厨师机
由内置函数组成的这个厨房,虽然功能强,但是毕竟有限,只能做那么千百道菜,不一定称心如意。你想吃的菜,厨房做不了怎么办?
这一点R贴心地考虑到了。你可以自己制作一台厨师机,做你独特的个性菜。
比如说,当年有一回全班考得都很惨,老师心软了,说为了提高及格率,把卷面分数开方乘十作为新分数吧。为了以后经常用来提高及格率,我们可以专门定义这样一个函数。继续以厨师机打比方的话,这道菜的菜名是“及格神器”,输入材料是“卷面分数”,输出的菜是“新分数”,那么我们可以这样制作这台厨师机:
及格神器 <- function(卷面分数) {
新分数 <- 卷面分数开方乘十
return(新分数)
}那么,调用这台厨师机做一份及格神器菜的方法就是:
及格神器(卷面分数= 40)翻译成R语言,就是这样的:
newscore <- function(x) {
y <- sqrt(x) * 10
return(y)
}以后当考了40分的时候,可以这样调用你的新函数:
newscore(x = 40)## [1] 63.24555 想一次可以用很久喔!有人说,学电脑的人,动脑筋就是为了偷懒。—《大家来学VIM》
上面这个例子中,自变量 x 只是用来在函数内部传递信息用的,不会影响函数之外的对象。看看这个例子:
x <- 36
y <- 81
newscore(x = y) # 函数内部的 x 把 81 的值接过来,而不是36。## [1] 90x # 函数外部的x仍然是36。## [1] 36很多厨师机需要输入多种原材料,也就是说,函数可以有多个自变量,例如:
news <- function(x, n) {
sqrt(x) * 10 + n
}
news(x = 36, n = 10)## [1] 70为了省事儿,可以按照函数要求的顺序来列出自变量的取值,省略自变量的名称。下面这条命令跟上一条完全等同:
news(36, 10) 但是,如果打乱了顺序,就必须指定谁是谁。
news(n = 10, x = 36)每次调用自定义函数 newscore() 的时候,必须提供所有自变量的取值,否则就会报错:
newscore()## Error in newscore(): argument "x" is missing, with no default为避免这个问题,我们可以给x个默认值,这样以后调用时,如果没有说x是多少的话,就按默认值计算:
newscore <- function(x = 36) # 将x默认值设为36。
{
sqrt(x) * 10
}
newscore()## [1] 60给函数定义时,我们用了花括号{},小贴士5.1说过,这意味着可以把一组操作都放进去,哪怕这一组操作有千万行,以后只用一行就可以调用一遍了!比如第5.3节提到过的人口指数增长,可以定义一个函数,名叫exponentialGrowth():
exponentialGrowth <- function(N0, r = 0.01, tmax = 10)
# 三个自变量:初始值,增长率(默认为0.01),时间(默认为10)。
{
N <- N0
for (t in 1 : (tmax - 1)) {
N[t + 1] <- N[t] + r * N[t]
}
return(N)
}函数return()是返回值,意思是告诉R,烹饪过程里其他的东西比如t都可以扔进垃圾箱了,只把N作为成品端出来当菜就行了。
以后再用到这个模型,比如计算初始值为80,增长率为每年2%,时间为100年,则用一条语句就行了:
plot(exponentialGrowth(80, 0.02, 100))如果你有多个自定义函数,经常需要在不同场合调用的话,为了方便,可以把这些函数写在一个文件里,例如叫做c:/r4r/myf.r,每次在R中使用source()函数运行这个文件就行了:
source('c:/r4r/myf.r')source()函数的作用就是运行指定文件里的所有代码。
图1.4就是用自定义函数作出的。只不过,那个厨师机不是我自己造的,而是我把别人制作的厨师机稍作了些改动,为己所用。
那么,别人是怎么把他自己的厨师机分享给我的呢?
9.3 扩展包:美食王国
上面我们自定义了几个函数,订制了几台私人专属厨师机。世界上很多角落都有想把 36 分变成 60 分的苦命同学,为了让他们也能方便地调用上文我们自定义的newscore()等函数,我们可以把它们打包上传到服务器上,这样别人下载了就可以直接用。我们打的这个包,就是扩展包。R包常用的服务器是CRAN和GitHub。当然你也可以用自己的服务器,只要别人能找得到下载地址就可以了。
一个扩展包,就是一套别人事先搭建的厨房。这样的厨房规模有大有小。小的厨房,可能只有一台厨师机(一个自定义函数);大的厨房,能有成百上千台厨师机。有时候,厨房(扩展包)还自带了一些食材(数据)让你试着品尝,比如我们前边使用的co2数据就是。
扩展包是 R 的生命力所在。找到一个合适的扩展包,能起到事半功倍的效果。甚至可以说,会用扩展包,比本书前半部分介绍的所有内容都重要!很多人用R就是奔着扩展包来的。
我们来举个例子。
北京的天安门广场,常年根据预测的日出日落时刻来确定升降国旗仪式的时刻。日出日落时刻的计算涉及复杂的天文学知识、三角函数知识、立体几何知识、天文学知识等,最要命的是还得有足够的耐心。我一直望而却步,直到有一天,我需要把某个气象站半年的气温数据(每半小时一条)分为白天和黑夜两组,那么就要判断当地每天的日出和日落时刻,不得不设法揭开这个神秘面纱了。花了大概一天的工夫,硬着头皮算出了个数,却跟实际对不上号。
后来,我惊喜地发现了maptools (Bivand and Lewin-Koh 2017)这个扩展包。安装这个包之后,用其中的sunriset() 函数一条指令轻松搞定。我们用它计算一下2017年国庆节天安门广场的日出日落时间,也就是升降国旗时刻。
install.packages("maptools") # 第一次使用某个扩展包时要先安装。require(maptools) # 调用包,让R把其中的函数读进R的脑子里。
position <- c(116.39, 39.91) # 天安门广场的经纬度。
mydate <- "2017-10-01" # 要计算的日期。
# 日出时刻:
sunriset(matrix(position, nrow = 1),
as.POSIXct(mydate, tz = "Asia/Shanghai"),
direction = c("sunrise"), POSIXct.out = TRUE)$time## [1] "2017-10-01 06:10:25 CST"# 日落时刻:
sunriset(matrix(position, nrow = 1),
as.POSIXct(mydate, tz = "Asia/Shanghai"),
direction = c("sunset"), POSIXct.out = TRUE)$time## [1] "2017-10-01 17:57:14 CST"跟官方公布的日出日落时刻比一比,看看是不是相同。
一个完整的扩展包包括了帮助信息,所以我们的F1小助理仍然管用。自己试试把光标移到sunriset按F1。
若要了解整个扩展包中所有的函数,可以用搜索引擎搜索 ‘cran maptools’,也可以在本地计算机 R 的安装路径下面 library 文件夹中找到。
虽然计算出了结果,但结果的展示方式我并不喜欢。这道菜我想再撒点胡椒粉,改成自己喜欢的口味。于是我更进一步,在扩展包已有函数的基础上自定义一个函数,计算任意一段时期的升降旗时刻:
# 函数名为flag,默认是计算2017年情人节开始一周内升降国旗时刻。
flag <- function(date.start = "2017-02-14", date.length = 7)
{
mydate <- seq(as.POSIXct(date.start, tz="Asia/Shanghai"),
by = 3600 * 24, length.out = date.length)
data.frame(
sunrise = sunriset(
matrix(c(116.39, 39.91), nrow = 1),
as.POSIXct(mydate, tz="Asia/Shanghai"),
direction=c("sunrise"), POSIXct.out = TRUE)$time,
sunset = sunriset(
matrix(c(116.39, 39.91), nrow = 1),
as.POSIXct(mydate, tz="Asia/Shanghai"),
direction=c("sunset"), POSIXct.out = TRUE)$time)
}
flag("2017-10-01") # 好了,以后调用这个函数就能很方便计算。## sunrise sunset
## 1 2017-10-01 06:10:25 2017-10-01 17:57:14
## 2 2017-10-02 06:11:24 2017-10-02 17:55:37
## 3 2017-10-03 06:12:23 2017-10-03 17:54:01
## 4 2017-10-04 06:13:22 2017-10-04 17:52:24
## 5 2017-10-05 06:14:21 2017-10-05 17:50:48
## 6 2017-10-06 06:15:21 2017-10-06 17:49:13
## 7 2017-10-07 06:16:21 2017-10-07 17:47:38再举个例子。CRAN 服务器上有几个专门为初学者写的扩展包,‘beginr’ (Zhao 2017a) 就是其中一个。这个包可以帮助初学者解决一些常见问题。而且,包里的函数结构都比较简单,初学者可以用F2调出函数的源代码修改练手。我们在这里做一详细介绍。
beginr的安装和加载的方法与其他包是类似的:
install.packages("beginr")下面,我们分类简要介绍一下其中的函数.
备忘函数
初学者用 plot() 作图时, 常常会忘记不同形状数据点(pch)对应的编号, 实线虚线(lty)的编号, 散点图类型(type)的代码, 以及最难选择的颜色代码。虽然可以上网搜,或者查看本书的小贴士3.2和3.3,但仍然不够快捷。现在, beginr 里提供了 plotpch(), plotlty(), plottype(), plotcolors()等函数, 想不起来的时候运行一下就行了。其实,这几个函数就是上面两个小贴士的来历。
beginr::plotpch()
beginr::plotlty()
beginr::plottype()
beginr::plotcolors()“包名称::函数”这种格式可以在不加载扩展包(library()或require())的情况下直接运行函数。上面这几个函数,有的不含自变量,有的采用的是自变量的默认值。
快速作图函数
线性拟合是数据处理的常见操作, 每次又是作图又是添加拟合方程,步骤繁琐。现在, 用beginr 里的一个 plotlm()函数就可以完成,畅快淋漓(图9.1)。
x <- 1:10
y <- 1:10 + rnorm(10)
beginr::plotlm(x, y, refline = TRUE)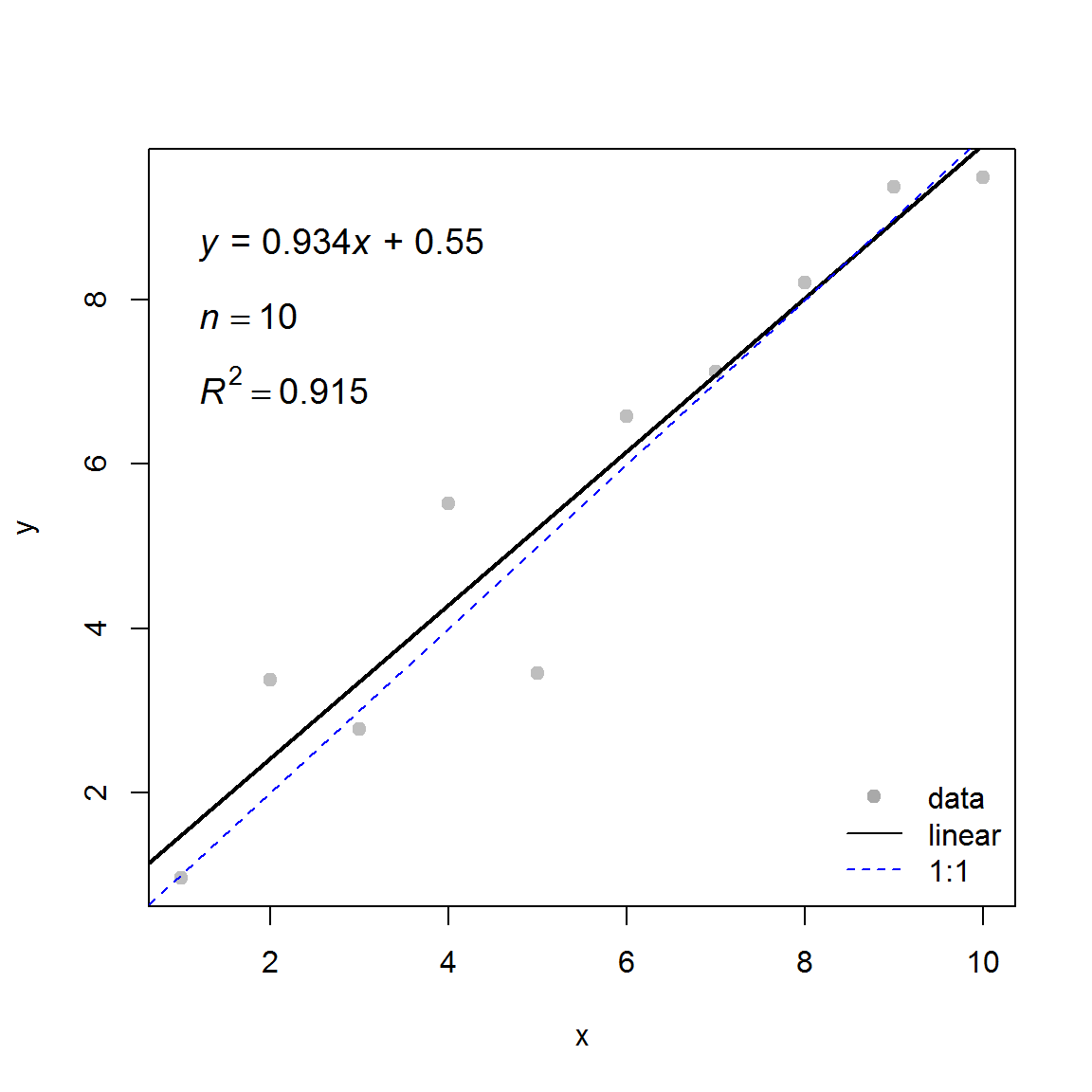
图 9.1: beginr::plotlm()函数示例.
## [[1]]
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.5500650 0.6258808 0.8788654 4.050975e-01
## x 0.9339774 0.1008698 9.2592346 1.503256e-05
##
## [[2]]
## [1] 0.9146516我们经常需要了解一组数据的分布, 看看是不是属于正态分布. beginr 里的 plothist() 函数不仅一步就做出直方图, 而且标出中值、 中位数、 四分位数、 标准偏差、 样本数, 以及用来判断是否正态分布的 skewness 值(图9.2).
x <- rnorm(10000)
beginr::plothist(x)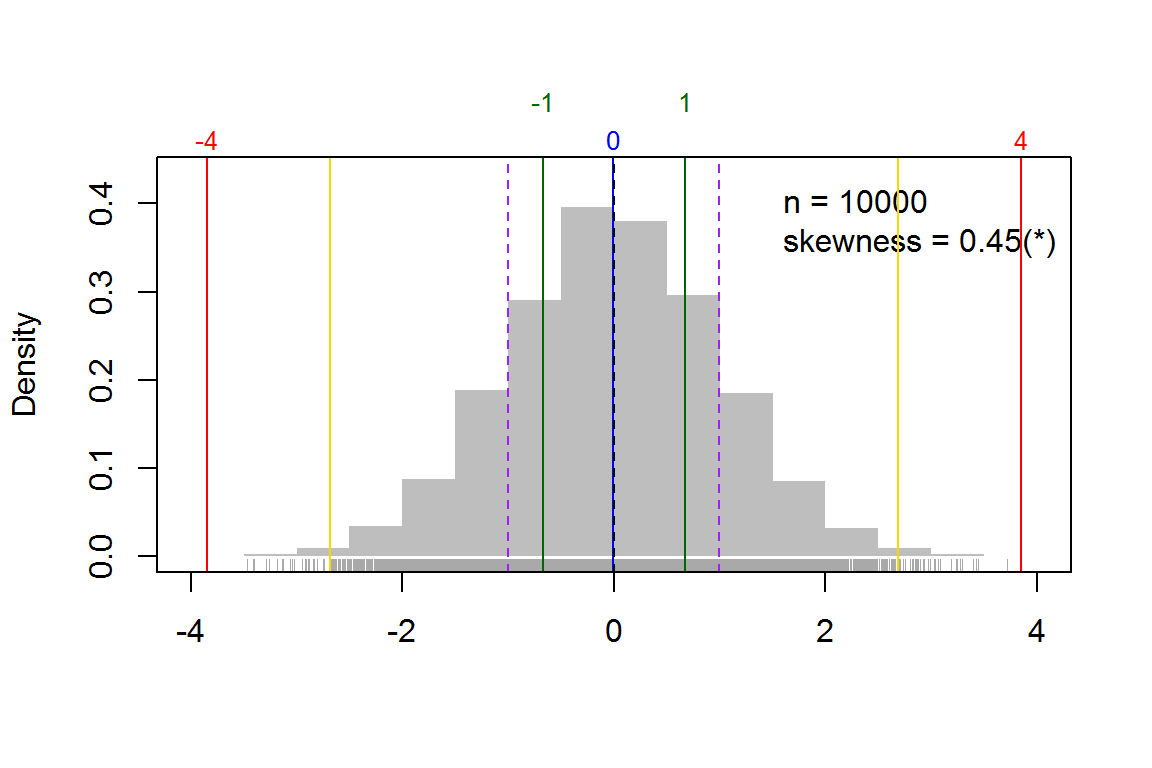
图 9.2: beginr::plothist()函数示例.
系统自带的成对儿散点图函数pairs()人见人爱, 只是功能再强大一点就好了。beginr 里的 plotpairs() 和 plotpairs2() 就是对其进行的扩展,也是图1.4的来历。
df <- data.frame(a = 1:10,
b = 1:10 + rnorm(10),
c = 1:10 + rnorm(10))
beginr::plotpairs(df)
beginr::plotpairs2(df)我们经常需要将一组自变量 (x) 和多组因变量 (y1, y2, …, yn) 在同一个坐标系作散点图图, 或者一组因变量 (y) 对多组自变量 (x1, x2, …, xn)作图, 并且画上各自的误差线。 beginr 里一条 dfplot() 或 dfplot2() 函数就能完成。
par(mfrow = c(1,2))
x <- seq(0, 2 * pi, length.out = 100)
y <- data.frame(sin(x), cos(x))
# 假定yerror是y的误差范围
yerror <- data.frame(abs(rnorm(100, sd = 0.3)),
abs(rnorm(100, sd = 0.1)))
beginr::dfplot(x, y, yerror = yerror)
beginr::dfplot2(y, x, xerror = yerror, xlab = '', ylab = '')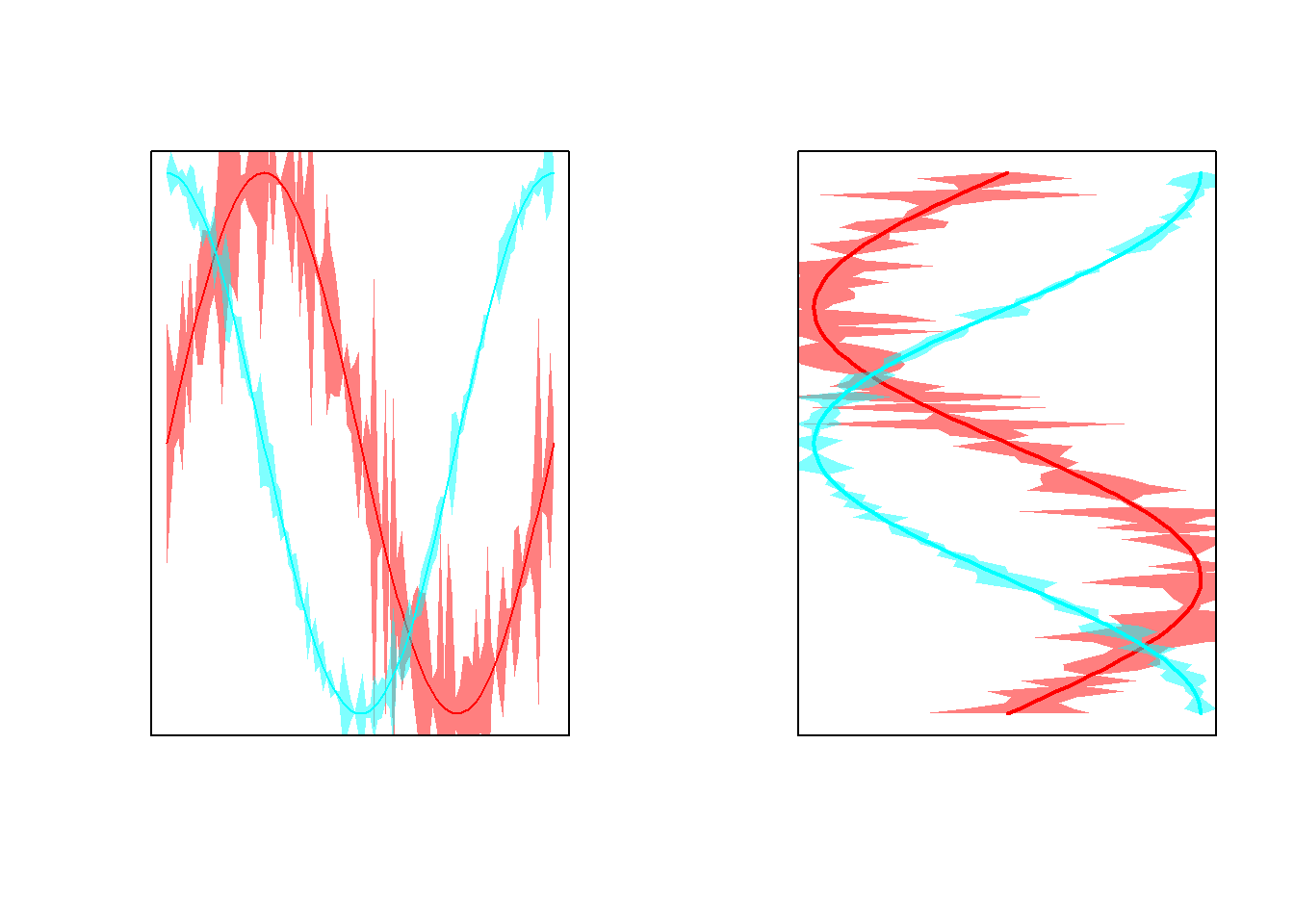
图 9.3: beginr::dfplot()和beginr::dfplot2()函数示例.
图9.3不同曲线的颜色默认状态下是函数自动选择的,或许不够美观,但对于初步查看数据来说已经足够了。当然也可以用指定的颜色作图。请查看该函数的帮助信息。
如果只是想简单地给散点图添加误差线,一般会用R基础包自带的arrow()函数逐步添加,而beginr里的 errorbar() 函数把多个步骤打了个包,一次性完成(图9.4).
x <- seq(0, 2 * pi, length.out = 100)
y <- sin(x)
plot(x, y, type = "l")
beginr::errorbar(x, y, yupper = 0.1, ylower = 0.1)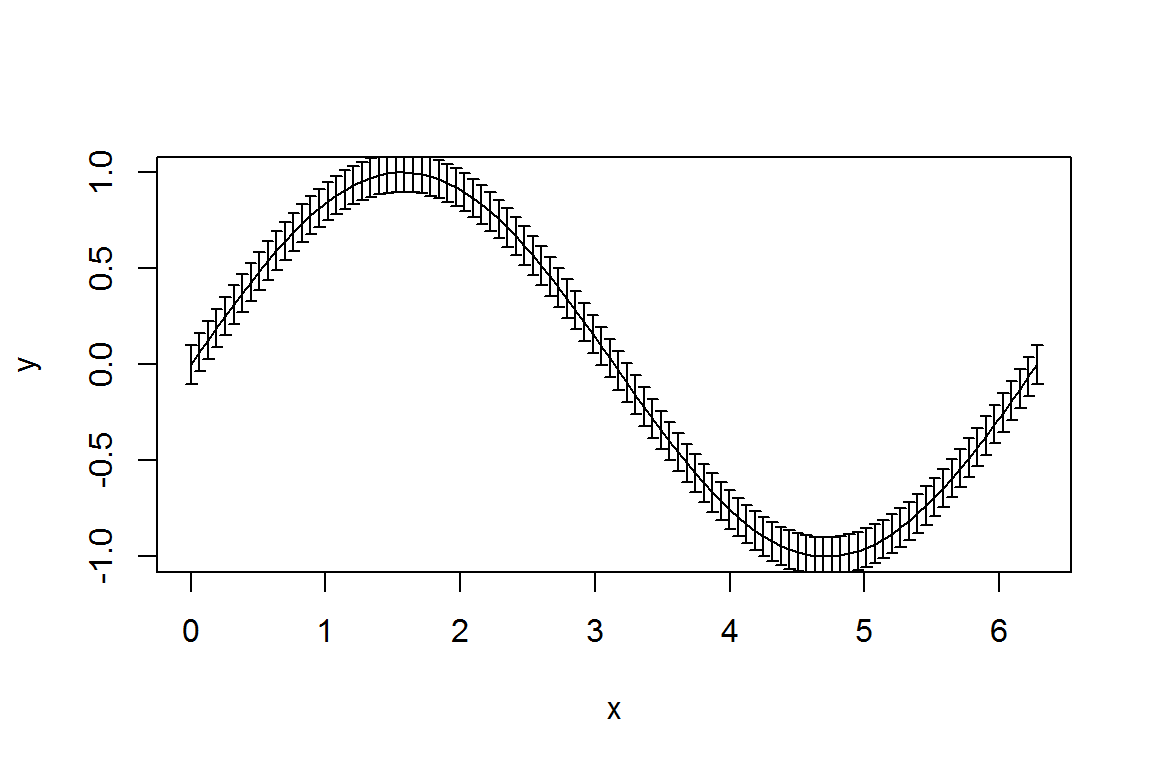
图 9.4: beginr::errorbar()函数示例.
数据框操作
beginr 提供了一些对数据框计算的函数, 例如计算多列数据里任意两列之间的相关性和线性拟合结果, 可以用 lmdf() 函数,可以方便地得到拟合直线的斜率、截距及其标准误差以及\(R^2\).
df <- data.frame(a = 1:10,
b = 1:10 + rnorm(10),
c = 1:10 + rnorm(10))
beginr::lmdf(df)## x y r.squared adj.r.squared intercept slope
## 1 a b 0.9684649 0.9645230 0.05392682 1.0633571
## 2 a c 0.8496167 0.8308188 0.94818582 0.8050753
## 3 b a 0.9684649 0.9645230 0.12432870 0.9107616
## 4 b c 0.8638982 0.8468855 0.94157582 0.7513098
## 5 c a 0.8496167 0.8308188 -0.17353688 1.0553257
## 6 c b 0.8638982 0.8468855 -0.27935054 1.1498561
## Std.Error.intercept Std.Error.slope t.intercept t.slope
## 1 0.4209397 0.06784057 0.1281106 15.674354
## 2 0.7430365 0.11975117 1.2760959 6.722902
## 3 0.3874815 0.05810521 0.3208636 15.674354
## 4 0.7030896 0.10543256 1.3391974 7.125975
## 5 0.9312734 0.15697474 -0.1863436 6.722902
## 6 0.9572968 0.16136123 -0.2918118 7.125975
## Pr.intercept Pr.slope
## 1 0.9012234 2.738982e-07
## 2 0.2377210 1.491470e-04
## 3 0.7565353 2.738982e-07
## 4 0.2173066 9.941349e-05
## 5 0.8568138 1.491470e-04
## 6 0.7778544 9.941349e-05文件读写函数
如果需要同时对多个数据文件进行处理, 逐个读入 R 里太麻烦. beginr 提供了个 readdir() 函数, 可以一次性把指定文件夹里所有数据读入, 保存在一个列表 (list) 里.
R 自带的 write 系列文件保存函数, 一不小心就把原有同名文件给覆盖了. beginr 提供了个安全的函数 writefile(), 避免一失足成千古恨.
list2ascii() 函数可以把一个列表原样保存成文本文件.
很多人引用了别人的工作却往往不列出参考文献. 不仅初学者常常如此, 很多学术论文里有些插图一眼就能看出是 R 的某个扩展包作出来的, 但参考文献里却没有列出来, 这往小了说是不尊重别人的工作,往大了说是缺乏学术道德. 对开源社区的生态圈是不利的. beginr 为初学者提供了 bib() 函数, 可以为指定的 R 扩展包生成文献引用信息。这个函数既可以打印出结果, 也可以直接保存为 ‘.bib’文件方便为 ’bookdown’ (Xie 2016) 或 ‘blogdown’ (Xie 2017) 调用,还可以方便地导入到其他文件管理软件里(如Endnote).
beginr::bib(pkg = c("mindr", "bookdownplus", "pinyin"))## @Manual{R-bookdownplus,
## title = {bookdownplus: Generate Varied Types of Books and Documents with R 'bookdown'
## Package},
## author = {Peng Zhao},
## year = {2017},
## note = {R package version 1.3.0},
## url = {https://CRAN.R-project.org/package=bookdownplus},
## }
## @Manual{R-mindr,
## title = {mindr: Convert Files Between Markdown or Rmarkdown Files and Mindmaps},
## author = {Peng Zhao},
## year = {2017},
## note = {R package version 1.1.0},
## url = {https://CRAN.R-project.org/package=mindr},
## }
## @Manual{R-pinyin,
## title = {pinyin: Convert Chinese Characters into Pinyin},
## author = {Peng Zhao},
## year = {2017},
## note = {R package version 1.1.0},
## url = {https://CRAN.R-project.org/package=pinyin},
## }事实上,bib()函数是受 knitr 包里的write_bib()函数启发而写成的。请比较一下两者的区别。
此外,beginr还有个rpkg()函数,可以帮助初学者开发自己的R扩展包,其用法将在下一节介绍。未来, beginr 包里还会增添新成员。
其实在本书前几课,早就有扩展包露出尖尖角了。在第7章,我们使用的R markdown (Allaire et al. 2016)就是个扩展包。当时生成的Word文档和幻灯片还比较简陋,现在有了更多的扩展包,我们就有了更多的选择。例如,xlsx (Dragulescu 2014)和ReporteRs (Gohel 2017)扩展包在R与Excel、Word和Powerpoint之间搭起了友好的桥梁,可以将他们结合起来,高效地生成漂亮的办公产品。
现在出个抢答题:按章节先后顺序,你猜,本书里最先用到的是什么扩展包?
赶紧往前翻!
找到了吗?
我们在第3章介绍了ggplot2 (Wickham 2009)和lattice (Sarkar 2008),他们是诸多绘图厨房里配备的最为华美的餐厅。
但是,很可惜,本书最先用到的不是他们。
本书文字里最先用到、并且最经常用到的扩展包,其实是一个叫做fortunes (Zeileis et al. 2016)的扩展包。这是个神奇包包。我们来安装调用运行一下,下面是见证奇迹的时刻:
install.packages("fortunes")require(fortunes)
fortune('Actually, I see it as part of my job')##
## Actually, I see it as part of my job to inflict R on people
## who are perfectly happy to have never heard of it. Happiness
## doesn't equal proficient and efficient. In some cases the
## proficiency of a person serves a greater good than their
## momentary happiness.
## -- Patrick Burns
## R-help (April 2005)这就是本书第1章开篇引用的那句话。别的章节出现的语录,很多来自这个扩展包,里面搜集的是R语言社区一些“自吹自擂”和“自省自黑”的语录,原文是英文,本书引用时被我翻译成了中文。老实说,第一次听说这个包的时候,我被雷到了,真不知道开发者是怎么想的,这个包平时没一点用处。直到写这本书的时候,发现里边的语录插在本书里倒是恰到好处。请呼唤小助理vignette('fortunes')来看看这个包的内容。
实际上,在本书用到的众多扩展包背后,隐藏着一个终极大boss,从本书的第一个字就开始用了:本书的写作环境和排版工具,不是Word,也不是\(\LaTeX\)26,而是bookdown 扩展包。书中漂亮的格式、准确方便的交叉引用、清晰的脚注和参考文献,全部是它完成的。
R语言走到今天,是一个聚沙成塔、集腋成裘的过程,其中的“沙”和“腋”,正是众多热心人花心血写成并奉献出来的扩展包。每个人献出一滴水,终于创造出如今的汪洋大海任你畅游。所以,使用别人慷慨贡献出来的扩展包,别忘了对开发者致谢。就像本书列出的参考文献那样,引用信息可以用citation()函数,例如:
citation("bookdown")##
## To cite the 'bookdown' package in publications use:
##
## Yihui Xie (2017). bookdown: Authoring Books and
## Technical Documents with R Markdown. R package
## version 0.5.
##
## Yihui Xie (2016). bookdown: Authoring Books and
## Technical Documents with R Markdown. Chapman and
## Hall/CRC. ISBN 978-1138700109
##
## To see these entries in BibTeX format, use
## 'print(<citation>, bibtex=TRUE)', 'toBibtex(.)', or
## set 'options(citation.bibtex.max=999)'.R的扩展包每年都在增加。现在到底有多少个扩展包呢?用这条命令:
length(unique(rownames(available.packages())))这是四个函数的嵌套,等同于:
a <- available.packages() # 获取所有扩展包的信息
b <- rownames(a) # 挑出扩展包的名称
c <- unique(b) # 去掉重复的名称
d <- length(c) # 数数有几个beginr 扩展包里有个 plotpkg()函数,可以绘制指定扩展包被下载的情况。例如,我们看一下 ‘rmarkdown’ 扩展包的下载趋势:
beginr::plotpkg('rmarkdown', from = '2014-01-01')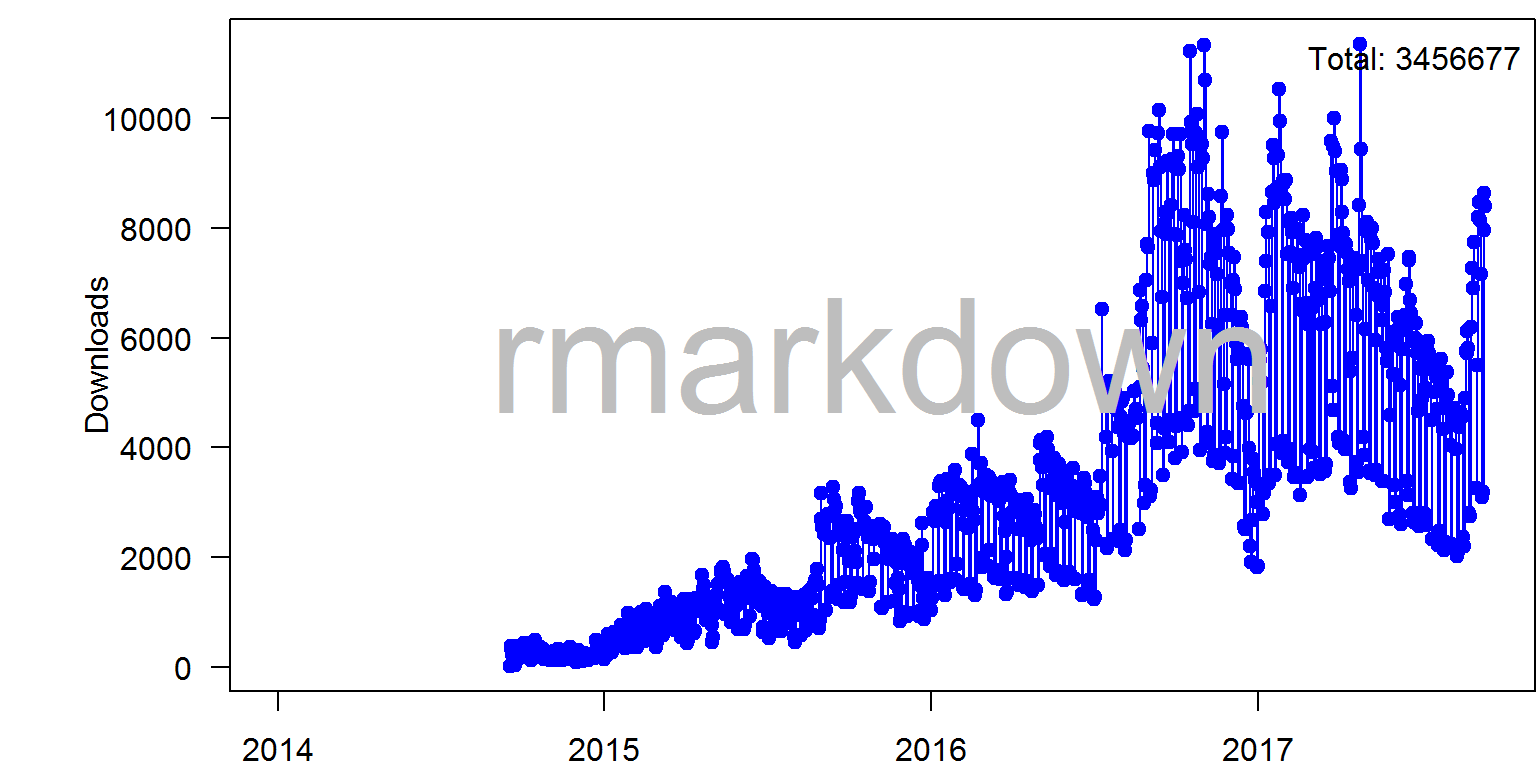
图 9.5: rmarkdown 扩展包日下载量趋势图.
这上万个厨房,被那些好心的作者们免费放在网上,让我们随心所欲安装回家;加上R的基础内置厨房,让R成为了一个超级美食王国。来尽情享受这饕餮盛宴吧!
Example 9.5 办公扩展包
请使用xlsx和ReporteRs扩展包,制作一个Excel、Word和Powerpoint文档。Example 9.6 制作动画
我们在学习循环的时候制作过动画。实际上,扩展包就有专门制作动画的。请自己找一个扩展包,制作一段动画。列出该扩展包的参考文献。Example 9.7 绘制风玫瑰图
风玫瑰图(windrose)是气象学常用的图形,显示的是一段时期内各个风向所占的比例。请找一个能够绘制风玫瑰图的扩展包,绘制一张风玫瑰图,并列出该包的参考文献。然而,“福兮祸之所伏”,在这包含了一万个扩展包的宝藏里,普通人很容易被贪欲吞噬而迷失自我,忘了自己的初衷。如何在这个大宝藏里找到适合自己的,以及自己想要的那一份?
继续请出法宝帮忙吧,网上搜,论坛问。CRAN的网页上有个“任务视图”27,针对这些包进行了粗略分类,例如空间数据分析、时间序列分析、生态和环境数据分析等。按你的目的去找就是了。
看着那些琳琅满目的扩展包,有种逛苹果商场看应用商店的感觉。有了这些五花八门三教九流的扩展包,我们就:
可上九天揽月,可下五洋捉鳖,谈笑凯歌还。
世上无难事,R包助通关。— 改自毛泽东《水调歌头·重上井冈山》
| 作用 | 函数 |
|---|---|
| 自定义函数 | function() |
| 查看可用扩展包 | available.packages() |
| 安装扩展包 | install.packages() |
| 调用扩展包 | require(), library() |
| 引用扩展包 | citation() |
9.4 包的开发:开疆拓土
开发 R 扩展包,听起来像是个浩大的工程,但是实际上并不难。学到这里,你完全可以开发自己的扩展包,在美食王国里开辟一片自己的天地。
扩展包的开发,最好的参考资料之一是 RStudio 公司首席科学家 Hadley Wickham 写的 R packages28一书,英文版可以在网上免费获取,有中文译本。这里,我们用最简短的篇幅,带你一起创建一个可用的扩展包,实际动手的时间前后不会超过十分钟。
第一步:准备
R包开发需要一系列辅助工具。除了下载安装 Rtools29外,运行 R 安装几个扩展包:
install.packages(c("devtools", "roxygen2", "knitr", "beginr"))第二步:创建新包
如果你已经安装了上一节介绍的扩展包’beginr’,那么只需运行下面的代码,就可以在工作目录得到一个名为rpkg/的文件夹。这就是我们的新包。
beginr::rpkg()下面,我们只需修改其中的两个文件就可以了。
第一个文件是 DESCRIPTION 文件。双击rpkg/的文件夹里的rpkg.Rproj,就会用RStudio打开该项目,然后点击右下面板 Files 标签下的 DESCRIPTION 文件。这个文件里是包的描述信息,包括包名,版本,标题,作者,维护者,描述等信息。把其中每一条冒号后面的信息改成我们自己的信息,不必要的行可以删除,例如可以改为:
Package: mypkg
Type: Package
Title: Calculate New Score
Version: 0.0.0
Author: Peng Zhao
Maintainer: Peng Zhao <pzhao@pzhao.net>
Description: Get a better score.
License: GPL
Encoding: UTF-8
LazyData: true按 ctrl+s 保存这个文件。第一个文件 DESCRIPTION 就修改完毕了。
第二个文件是右下面板 Files 标签下的 R/foo.R 文件。这是存放我们自定义函数的地方。打开这个文件,把其中的内容全部删掉,换成自己的函数,例如前面提到的及格函数 newscore。
newscore <- function(x) {
y <- sqrt(x) * 10
return(y)
}然后,将光标移到函数名称的位置,按快捷键 ctrl+shift+alt+r,函数前面就自动添加了几行信息。我们需要将信息填写完整:
- 首行是函数的标题,一般用来简要描述函数的作用。这里我们将 ‘Title’ 改成 ‘Calculate new score’;
#' @param x一行用来介绍自变量。我们在后面添加文字old score;#' @return一行用来介绍函数的返回值。在后面添加文字new score;#' @examples一行用来举例子。在后面添加文字newscore(49)。
最后得到的文件内容是这样的:
#' Calculate new score
#'
#' @param x old score
#'
#' @return new score
#' @export
#'
#' @examples newscore(49)
newscore <- function(x) {
y <- sqrt(x) * 10
return(y)
}我们上面填写的信息当然是不够详细的,但是不要紧,作为一个测试包已经够用了。
好了,一个新包已经写完了。
第三步:编译和本地安装
按ctrl+shift+b,或者点击RStudio右上模板Build标签下的Build & Reload按钮,包就自动编译、安装和加载好了!祝贺!
现在,我们可以像使用别人的包一样使用自己的包了。例如,运行一下刚才自定义的 newscore()函数:
library(mypkg)
newscore(36)## [1] 60还记得小助理example()吗?
example(newscore)##
## newscr> newscore(49)
## [1] 70把光标移到函数名 newscore 上,按F1键,帮助信息就在右下面板的Help标签下出现了:
Calculate new score
Description
Calculate new score
Usage
newscore(x)
Arguments
x old score
Value
new score
Examples
newscore(49)
将这个帮助信息跟我们在 foo.R 里填写的说明信息对比,就会明白帮助信息里每处的说明是怎么来的了。你可以在 foo.R 里如法炮制,添加更多的自定义函数,重复上面的编译过程。
我们新建的这个扩展包,就是我们在 R 扩展包美食王国里开拓的属于我们自己的疆土。
简单来说,运行beginr::rpkg() – 修改 DESCRIPTION 和 R/foo.R – 编译成包,这就是我们提出的 “R 包开发极简三步曲”。
当然,也可以在 RStudio 里通过点击菜单栏来创建新包,但我们仍然建议从 beginr 出发来创建新包,更为简易,也更容易理解开发 R 包的工作流程。
欲穷千里目,更上一层楼。用极简三部曲写出的 R 包,已经足够自用。在这个高度,看到的风景已经够美。你可以在这个水平的观景台休整休整,再考虑是否继续往上攀登。孔子登东山而小鲁,登泰山而小天下。如果想看到更高处的风景,那么就继续下一步。
第四步:发布和分享
只有把扩展包发布和分享出去,包才会得以充分利用,得到更多用户的建议和改进,才真正有了生命力。正如史书分正史和野史,R 包可以根据发布和分享方式分为“正包”和“野包”。
正包,就是通过R官方认可并且发布在CRAN网站上的,等于领到了认证和许可,可以用 install.package() 直接安装,我们前面已经接触了很多;而野包就是自己私下写的,随便放在自己喜欢的地方小范围使用的。很多包转正之前都是野包,经过反复测试和升级后才转的正,而有的野包会永远野下去;很多包转正之后仍然保留野包作为开发版,将野包升级到一定程度后再次转正。这是个自由的世界。
这里,我们主要介绍野包的发布和分享方法,而对于转正的方法仅作简略介绍。
野包的发布方法首推 GitHub 法。熟悉GitHub的话,建议用这种方法。既然熟悉,我们这里就不赘述GitHub的用法了。简单来说:
你要做的,就是在github.com上申请个账号,电脑里安装个客户端,在客户端新建个项目并起个名字例如叫 mymickey ,把你新的R包文件夹同步上去,就可以通知用户们来使用你的 mymickey 包了。
用户要做的,就是在R里运行
devtools::install_github("你的账号/你的项目名称")就把你的包装到他们的R里了。
举例来说,beginr 这个扩展包的开发版就是这样在GitHub发布的,从GitHub安装的方法是:
devtools::install_github("pzhaonet/beginr")如果你不喜欢 GitHub 的用法,那么可以用离线法发布:让用户把包的压缩文件先下载到他们电脑上,再用R包的离线安装方式。包的压缩文件其实在编译时已经自动生成了。去看看你电脑上的 R 包文件夹,跟它并列存放的,有个与包同名的.tar.gz压缩文件。这就是离线安装包。下面:
你要做的,就是随便以任何方式,不管是email、qq、网盘,还是优盘、手机、移动硬盘,只要让用户能得到你这个压缩文件就行了。
用户要做的,就是拿到文件后在他们的电脑上安装,方法是在 RStudio 菜单栏点
Tools–Install Packages–Install from Package Archive File,选上你的包,就行了。
上面讲的是野包的发布分享方法。如果想提交到 CRAN 转正,其实也不难,这里给出主要步骤:
自查。包发布之前,先自查有没有错误。只需用RStudio打开待发布的R包的
.Rproj文件,然后点击右上方面板的 Build – Check 按钮,就可以看到自查结果。确保其中没有任何错误和警告,否则就要修改。提交。把包的压缩文件
.tar.gz在 CRAN 的提交网页30上传即可。成功上传后会收到 email 通知,需要点击里面的链接进行确认。确认后进入 CRAN 的自动检查状态。如果包的毛病太多的话,系统会自动发拒信,并给出拒绝理由。按理由去修改,重修提交即可。修订。如果通过了 CRAN 自动检查,就进入人工检查阶段。运气好的话,几乎在提交当天就会收到管理员的邮件,指出包的不足和修改意见。只需按意见修改,并且在 DESCRIPTION 文件里把版本修改成新的号码,重新编译再次上传就可以了。对于新手来说,这个过程可能会反复几个回合,有时候得到的修改意见可能比较苛刻,需要一些耐心。管理员不计酬劳义务做这项工作,请对他们保持足够的礼貌和尊重。
从上面介绍的步骤可以看出,R 包的开发就像往学术期刊投稿一样繁琐耗时。那么,让我们回过头来谈一个问题:我们为什么要开发 R 包?
这个问题见仁见智,我说说从自己开发 R 包的体会。
首先是方便自用。
使用 R 语言这几年里,我逐渐积累的自定义函数越来越多,我把他们通通存到一个 ‘myfunction.R’ 文件里。现在,这个文件已经有 3000 多行,将近 100 个自定义函数,越多越记不住,用时查找越来越困难。有个相对简单的方法,就是每次用时都运行source('myfunction.R'),稍微方便一些,虽然会导致 RStudio 右上面板 Environment 标签下特别冗长,而且经常忘记这些函数的用法,需要查看函数源代码,但总好过每次把函数重写或重拷贝一遍。没写成包之前,这几年都是这么过来的。
如今,我把这些函数写成了一个野包,取名’mf’,并分享到了 GitHub31上。这个包纯属自用,帮助信息写得不够齐全和详细,但自己懂就行了,用起来的爽快程度,当然比source()强多了,不仅Environment区清爽了,更关键的是,忘了的话就用 tab 和 F1 大法,几年积攒的不快一扫而空。就算换个工作单位,换台电脑,花几秒钟安装后照旧调用,处处无家处处家。
其次是改善代码。
写代码对我来说一直是件封闭的事情:自己写,自己用,一旦出错,只有自己知道。计算方法没有经过同行评议,出错的风险很大。但是我又不愿意厚着脸皮强迫别人帮我改代码。两全的办法,就是开源,写成包,放在 GitHub 上,接受志愿者挑错,有则改之无则加勉。只有这样,才能把代码错误越来越少,改得越来越好,最终还是自己用起来更放心。我有几个包在发布之后,很快得到了别人的修改意见,这才知道哪里可以改进。与此同时,代码也可以方便别人使用,利人利己,何乐不为?
最后是审视自我。
我的第一个 R 包postr是用 R markdown 做海报,兴致勃勃地放到 GitHub 第一天,就有人留言汇报问题。我知道,这只是个开始,以后会有更多的问题,里面会有赞美,可能也会有谩骂。写出个R包真的不算啥,等待在前面的一个又一个的坑才是让人真正头疼的事情。
这个阶段就要接收考验了。你会重新审视自己:我这么干到底是图个啥?我自用已经够了,却要花大量的时间帮一些跟我八杆子都打不到的人解决他们五花八门层出不穷的问题,我闲得么?花的这工夫和精力,到底是能发表成学术论文呢,还是能变现呢,还是能替我洗碗带孩子呢,还是能帮我赚游戏装备?
开源软件是面镜子,从中可以看见开发者的影子;开发R扩展包,可以从中看见自己。唐太宗说过:
以铜为鉴,可以正衣冠;
以人为鉴,可以知得失;
以史为鉴,可以知兴替:
以 R 包为鉴,可以知本我、自我和超我。9.5 课外活动:餐后甜点
上大学的时候,在食堂吃完午饭,我们会玩几分钟扫雷游戏,时间短,乐趣多,健脑益智,而且随时可以停下来。
扫雷是旧版Windows自带的经典小游戏,可惜Window 7之后,扫雷就不再是默认安装了。不要紧,我们可以在R中玩扫雷,因为有这样的扩展包在。
请用搜索引擎找到有扫雷游戏的扩展包,安装,并且试玩。这个扩展包里,包含了第1章对R表白时绘制那颗中国心的秘密。你能找到这个秘密吗?
看看你的扫雷记录吧。比比看,谁能登上扫雷英雄榜!
References
Bivand, Roger, and Nicholas Lewin-Koh. 2017. Maptools: Tools for Reading and Handling Spatial Objects. https://CRAN.R-project.org/package=maptools.
Zhao, Peng. 2017a. Beginr: Functions for R Beginners. https://CRAN.R-project.org/package=beginr.
Xie, Yihui. 2016. Bookdown: Authoring Books and Technical Documents with R Markdown. Boca Raton, Florida: Chapman; Hall/CRC. https://github.com/rstudio/bookdown.
Xie, Yihui. 2017. Blogdown: Create Blogs and Websites with R Markdown. https://github.com/rstudio/blogdown.
Allaire, JJ, Joe Cheng, Yihui Xie, Jonathan McPherson, Winston Chang, Jeff Allen, Hadley Wickham, Aron Atkins, and Rob Hyndman. 2016. Rmarkdown: Dynamic Documents for R. https://CRAN.R-project.org/package=rmarkdown.
Dragulescu, Adrian A. 2014. Xlsx: Read, Write, Format Excel 2007 and Excel 97/2000/Xp/2003 Files. https://CRAN.R-project.org/package=xlsx.
Gohel, David. 2017. ReporteRs: Microsoft Word and Powerpoint Documents Generation. https://CRAN.R-project.org/package=ReporteRs.
Wickham, Hadley. 2009. Ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. http://ggplot2.org.
Sarkar, Deepayan. 2008. Lattice: Multivariate Data Visualization with R. New York: Springer. http://lmdvr.r-forge.r-project.org.
Zeileis, Achim, the R community. Contributions (fortunes and/or code) by Torsten Hothorn, Peter Dalgaard, Uwe Ligges, Kevin Wright, Martin Maechler, Kjetil Brinchmann Halvorsen, et al. 2016. Fortunes: R Fortunes. https://CRAN.R-project.org/package=fortunes.