第10章 字符
你会发现一个奇特的现象:很多人使用R多年,已经能够用R做很多事情,但是他们却从不自诩懂得了这门语言。— Luis Argerich
前边很多章节都用到了字符串类型的变量,例如作图的图例、表达式、坐标轴的标签,读写文件时文件的路径,数据框的行列名称等。显而易见,字符串的运算不是加减乘除,而是连接、分割、截取、查找、替换。
为什么要学习字符串的处理呢?对因子操作时,保存文件时,或是作图要添加文字时,如果懂得如何处理字符串,这些任务就会很方便完成。放眼望去,字符串充满了我们的世界,有了R这个利器,我们就可以做很多想做的事。比如前几年方舟子对韩寒的作品进行的文本分析,等我们学完本章之后,我们也可以做。
10.1 狐狸从懒狗身上跳过
让我们从这样一句话开始:
The quick brown fox jumps over the lazy dog.不知你有没有注意到,这句话经常在电脑软件看到。敏捷的褐色狐狸从懒狗身上跳过?这是什么意思?
据说,在很久以前的打字机时代,打字机需要测试每个键都能打出字来。为了省纸省墨,打字员就去打这样一句话,英文里所有的26个字母都包含在这个简短的句子里,所有字母的字体效果一目了然。这个文字游戏叫做“全字母句”(pangram)。字母重复出现的次数越少越好(我表示不懂:把键盘上的键挨个儿敲一遍是不是更省脑子……)。
真有这么神奇?上面这句话里,真的包含了全部的26个字母吗?有哪些字母重复出现过,出现过几次?
我们用R来试试,边玩边学字符处理函数。
这个游戏里,我们不区分字母的大小写,T和t算是同一个字母。所以,我们第一步先用tolower()函数或者toupper()函数,把全部字母转换成小写或大写。
x <- 'The quick brown fox jumps over the lazy dog'
xlower <- tolower(x)
class(xlower)## [1] "character"class()函数返回的结果显示,这确实是个字符变量。下面看看字符的长度:
length(x)## [1] 1nchar(x)## [1] 43nchar()用来查看字符串的长度。注意它跟length()的区别。后者是查看向量中元素的个数。x向量里只有1个元素,这个元素包含的字符数是43。
R 用成对儿的单引号或双引号来表示字符和字符串。其实前面我们已经接触过了,比如读入或存储文件时需要用到文件名,就是个字符串:
myfile2 <- "c:/r4r/co2.csv"第二步,我们用字符串分割函数strsplit(),将x这个字符串拆分成单个字符。
xsingle <- strsplit(xlower, '')[[1]]
nchar(xsingle)## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [29] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1length(xsingle)## [1] 43请在这里再次体会一下nchar()函数与length()函数的区别。
第三步,我们看看第一个字符是否在别的地方出现。可以用grep()函数(global regular expression print的缩写):
grep(xsingle[1], xsingle)## [1] 1 32返回的结果显示了第一个字符t在整个句子中出现的位置。
后面的就是重复操作了,逐个检查每一个字符就行。这提醒我们,应该用循环语句:
for (i in 1:length(xsingle)) print(grep(xsingle[i], xsingle))## [1] 1 32
## [1] 2 33
## [1] 3 29 34
## [1] 4 10 16 20 26 31 35 40
## [1] 5
## [1] 6 22
## ......print()函数的作用是将结果打印在操作台。这样就得到了每个字符在句子中重复出现的位置。在多个位置出现的,自然就是重复的字母了。
这个输出结果不够明显,要是能同时显示是哪个字符就好了。这个好办,我们用字符串连接函数paste(),将字符名称跟出现位置连起来后再打印就行了:
for (i in 1:length(xsingle))
print(paste(xsingle[i], grep(xsingle[i], xsingle)))## [1] "t 1" "t 32"
## [1] "h 2" "h 33"
## [1] "e 3" "e 29" "e 34"
## [1] " 4" " 10" " 16" " 20" " 26" " 31" " 35" " 40"
## [1] "q 5"
## [1] "u 6" "u 22"
## ......除了paste()函数,另外还有猫函数cat()可以用——当然,cat在这里不是猫,而是concatenate的缩写。
由于学过了第5.5节,一看是循环,我们就考虑一下能不能超越循环,改为向量操作:
sapply(xsingle, function(x) grep(x, xsingle))## $t
## [1] 1 32
##
## $h
## [1] 2 33
##
## $e
## [1] 3 29 34
## ......得到的结果跟上一条指令是一致的。
我们已经得到了期望的结果,虽然输出的格式难看点。好看一点的输入结果,可以用table(), duplicated()和unique()三姐妹。
表格函数table()计算的是每个元素出现的个数:
table(xsingle)## xsingle
## a b c d e f g h i j k l m n o p q r s t u v w x y z
## 8 1 1 1 1 3 1 1 2 1 1 1 1 1 1 4 1 1 2 1 2 2 1 1 1 1 1“重复函数”duplicated()可以查找是否有重复元素。
duplicated(xsingle)## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [10] TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE
## [19] FALSE TRUE FALSE TRUE FALSE FALSE FALSE TRUE TRUE
## [28] FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## [37] FALSE FALSE FALSE TRUE FALSE TRUE FALSE哪些字符第二次出现,哪些就返回TRUE。
结合逻辑运算符和元素的下标系统,就可以显示哪些字母没有重复:
xsingle[!duplicated(xsingle)]## [1] "t" "h" "e" " " "q" "u" "i" "c" "k" "b" "r" "o" "w" "n"
## [15] "f" "x" "j" "m" "p" "s" "v" "l" "a" "z" "y" "d" "g"这跟“不重复函数”unique()返回的结果是一样的:
unique(xsingle)## [1] "t" "h" "e" " " "q" "u" "i" "c" "k" "b" "r" "o" "w" "n"
## [15] "f" "x" "j" "m" "p" "s" "v" "l" "a" "z" "y" "d" "g"总共有多少个不同的字符呢?
length(unique(xsingle))## [1] 27结果里包含了空格字符。由此我们可以确定,26个字母的确全在这个狐狸句子里了。
10.2 千字文的重复字
英文的全字母句很短,找重复的字母,就算不编程,瞪大眼睛数也能数得出来。但是,如果字数太多,眼睛就不好用了,比如我国的传统启蒙经典《千字文》。
十五个世纪前,南朝梁武帝令大臣周兴嗣把王羲之写过的1000个汉字连成一篇文章,增加临帖练字的便利和趣味性。周兴嗣冥思苦想,一夜未眠,东方既白,大作已成,镜子一照,黑发尽如雪。
这篇奇文大概是最接近“全字母句”要求的汉语文章。《千字文》最大的亮点是“字不重复”,但是,却有人提出质疑,认为有的字出现了重复,重复的字数众说纷纭,有的说1个,有的说6个,还有人说有7个。
现在,我们来用R语言来找找千字文里到底有几个重复字。
首先从网上找到千字文的全文。我们选择的是“古诗文网”32提供的版本,事先已经保存成了一个文本文件。下面的这条命令,将从我们的服务器上把这个文本文件下载到你的本地硬盘。
download.file(url =
"http://dapengde.com/r4rookies/qianziwen.txt",
destfile = "c:/r4r/qianziwen.txt")这个文件是个纯文本文件,可以用记事本打开,不像我们以前常用的表格数据。这样的文本,我们用readLines()函数读取,得到的是个字符串向量。
qzw <- readLines('c:/r4r/qianziwen.txt', encoding = 'UTF-8')
class(qzw)## [1] "character"length(qzw) #向量长度## [1] 249nchar(qzw) #向量里每个元素包含的字符数## [1] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [29] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [57] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [85] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [113] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [141] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [169] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [197] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0
## [225] 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9 0 9如果想借用前面处理英文句子方法,那么我们先得把这个向量打散后合并成一个元素:
qzwmerged <- paste(qzw, collapse = '')上次我们宽容地把空格留下了,这回我们把它踢出去,免得干扰计数。这可以用替换字符函数gsub()来完成:
qzwmerged <- gsub(' ', '', qzwmerged)
nchar(qzwmerged)## [1] 1000得到的是整整1000个字了。字符替换函数另外还有sub()函数和chartr()函数。有什么区别?问你的小助理。
现在我们得到的千字文,跟狐狸懒狗一样,成了一句话,就可以用完全相同的方法来检验了:
qzwsingle <- strsplit(qzwmerged, '')[[1]]
chardup <- qzwsingle[duplicated(qzwsingle)]
for (i in chardup) print(paste(i, grep(i, qzw, value = TRUE)))## [1] "发 吊民伐罪 周发殷汤" "发 盖此身发 四大五常"
## [1] "义 节义廉退 颠沛匪亏" "义 俊义密勿 多士实宁"
## [1] "实 策功茂实 勒碑刻铭" "实 俊义密勿 多士实宁"
## [1] "云 云腾致雨 露结为霜" "云 岳宗泰岱 禅主云亭"
## [1] "昆 金生丽水 玉出昆冈" "昆 昆池碣石 钜野洞庭"
## [1] "戚 欣奏累遣 戚谢欢招" "戚 亲戚故旧 老少异粮"
## [1] "洁 女慕贞洁 男效才良" "洁 纨扇圆洁 银烛炜煌"
## [1] "并 九州禹迹 百郡秦并" "并 释纷利俗 并皆佳妙"果然,有8个字重复了!那么,千字文号称没有一字重复是学术造假么?
这就牵扯出简体字和繁体字的恩怨了。例如,表面上“发”字重复出现在“周发殷汤”句和“盖此身发”句,但原文其实为“周發殷汤”“盖此身髮”。“發”读第一声,是武王姬发的名字;“髮”读第四声,是头发。这大概是最常见的混淆了。有些理发店把店名写作“理發店”,卡拉OK把“发如雪”写成“發如雪”,都弄错了。周潤發以前给百年潤髮的洗发水做广告,更加深了这种误会。
再如“云”出现在“云腾致雨”句和“禅主云亭”句,原文为“雲腾致雨”“禪主云亭”,“雲”是云彩,“云”是泰山脚下的一座山名为“云山”,封禅之地。繁体字“雲”和“云”完全是两个不同的字。
此外,古诗文网提供的这个版本有错别字,比如错把“俊乂密勿”写成了“俊义密勿”而导致跟“节义廉退”的“义”字重复。
10.3 整理读书笔记
不管是全字母句还是千字文,找重复的字只是个趣味游戏,没什么实际用处。下面,我们用字符串的处理方法来做一件有用的事:整理文本。
我有很多朋友爱读书,或早或晚入手了 Kindle电子书阅读器,从此陷入了读书的大坑里不能自拔。而我在使用了一年之后,把Kindle 上的常规操作都熟悉了,但只有一个问题没有好好解决:整理笔记和高亮文本。
Kindle 的笔记和高亮文本都保存在Kindle的根目录下documents文件夹里名为“My Clippings.txt”的文本文件里,在电脑中可以用记事本中直接打开,看上去是图10.1的效果。文本是按做笔记的时间顺序逐条列下去的,非常凌乱。如果能整理成表格,按照自己需要的顺序来排列就好了。
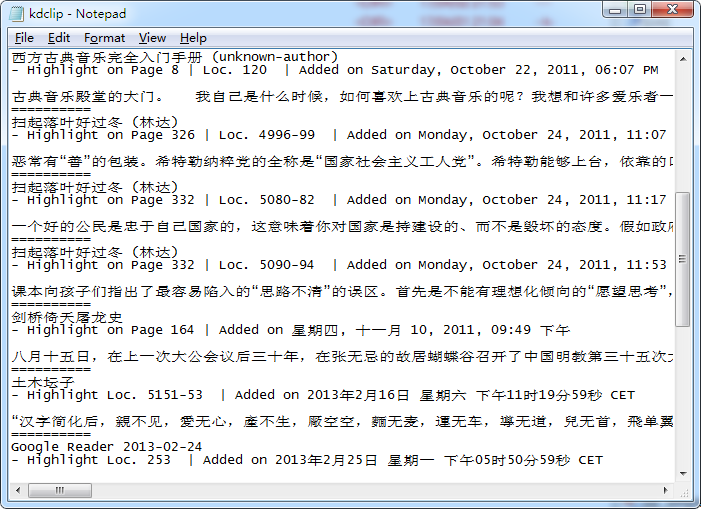
图 10.1: 电子阅读器的读书笔记
对此,网上倒是有现成的方法对笔记进行整理,比如下载Word的宏,或有人写了专门的软件,或在线转换,但要么是有安全隐患,要么是要收费,要么是不支持中文。最不爽的,是不能随心所欲。
R用久了,就会习惯了一双自由的翅膀,和一颗任性的心。现在,我们用R把笔记整理到表格里,并把来自同一本书的内容排在一起。
这里,我们提供一个示例文件,仍然是来我们服务器上下载,并读入R:
download.file(url =
"http://dapengde.com/r4rookies/kdclip.txt",
destfile = "c:/r4r/kdclip.txt")aa <- readLines("c:/r4r/kdclip.txt", encoding="UTF-8")我们先用记事本或别的软件打开这个文本,观察一下它的结构。每条笔记占4行,依次是书名,书中的位置和做笔记的时间,空行,笔记内容,两条笔记之间的间隔符。我们要做的事情是,生成一个表格,第一列是书名,第二列是笔记内容。
我们先把所有笔记的标题找出来,保存在一个叫title的向量里:
length.aa <- length(aa)
title <- aa[c(seq(1, length.aa, by = 5))]然后,用排序函数order(),对所有的标题按字母排序:
title.o <- order(title)
title <- title[title.o]接着,摘取笔记的高亮内容,存在叫highlight的向量里:
highlight <- aa[c(seq(4, length.aa, by = 5))][title.o]最后,把这两个向量保存在一个数据框里,大功告成,数据框保存到硬盘里。
kn <- data.frame(Title = title, Highlight = highlight)
write.table(kn, "c:/r4r/kn.txt",
sep = "\t", row.names = FALSE)保存文件时我们用得分隔符sep参数为\t,表示用制表符tab分隔。用Excel打开我们整理的表格看看吧!
也许你还不够满意:嗯,要是,笔记位置和做笔记的时间信息也放进表格里备案就好了。这好办,我们先把包含信息的行都提取出来。
location <- aa[c(seq(2, length.aa, by = 5))][title.o]
location[1]我们发现,笔记位置的信息的格式是统一这样的:每行从第13个字符开始,到Added on倒着数到第5个字符之间,就是笔记位置的信息;而Added on里的第一个字符往后数第10个字符起,到这一行的末尾就是做笔记的时间。那么,我们用字符查找函数regexpre()来找到Added on出现的位置,然后用字符截取函数substr()截取信息就可以了
time.aa <- substr(location,
(regexpr(" Added on ", location) + 10) ,
nchar(location))[title.o]
loc <- substr(
location, 13,
regexpr(" Added on ", location) - 5)[order(title.o)]
kn <- data.frame(Title = title, Highlight = highlight,
Loc = loc, Time = time.aa)
write.table(kn, "c:/r4r/kn2.txt",
sep = "\t", row.names = FALSE)看看新表格,是不是信息齐全了?
用这样的方法,不仅可以把笔记整理成表格,还可以对笔记进行再加工,例如计算笔记中某个关键词出现的频数,每本书做笔记的条数;还可以根据时间信息,来看看自己哪段时间读书多,看看自己的读书兴趣如何随时间在转移。随心所欲, 想怎么玩就怎么玩。如果这里介绍的函数仍然不能满足你的需求,还可以使用stringr扩展包(Wickham 2017),里面提供了更加强大的工具。
Example 10.2 中文是博大精深的,除了1000字不重复的千字文以外,我们还有一部《中华字经》。
字经的官方网站33介绍说:
世界上最奇妙的汉字学习课本。……全文4000汉字没有一个字是重复使用的。
字经包括了常用汉字3500个。该网站是国际网站,有繁体字版,还有英文介绍:
The book does not repeat any characters…… “Chinese Character Canon” is a poem composed of 4,000 characters…
人民日报对此报导说:
中华字经共收录无重复汉字4000个。请用R语言看看中华字经是不是真的没有一字重复。如果有,是哪些字,各重复出现了几次,是什么原因造成了重复?
此外,中华字经是否真正包括了常用汉字3500个?| 函数 | 作用 |
|---|---|
readLines(), writeLines() |
按字符读取和保存文本文件 |
tolower(), toupper() |
大小写转换 |
nchar() |
字符个数 |
strsplit(), substr(), substring() |
字符串分割和截取 |
paste(), cat() |
字符连接 |
grep(), gsub(), sub(), chartr() |
查找和替换 |
table(), unique(), duplicated() |
计数,查重(不限于字符变量) |
10.4 课外活动:张无忌的困惑
金庸的小说《倚天屠龙记》后记中写到:
张无忌却始终拖泥带水,对于周芷若、赵敏、殷离、小昭这四个姑娘,似乎他对赵敏爱得最深,最后对周芷若也这般说了,但在他内心深处,到底爱哪一个姑娘更加多些?恐怕他自己也不知道。张无忌到底爱谁?对于这个问题,已经有人用R语言的字符处理方法进行研究了,研究的大体思路是,看看哪个姑娘的名字在书中出现的次数最多,尤其是跟张无忌的名字同时出现的次数最多。最后,R代码得出了结论,张无忌最爱的其实是……请上网搜吧。
发挥你的想象力,看看利用类似的方法,能否对你喜欢的作品进行分析,得到一些有趣的观点。例如,
贾宝玉最常跟哪个女孩在一起;
诸葛亮和周瑜在三国演义里的对手戏出现过几次;
西天取经路上前后有多少妖精要吃唐僧肉;
晁盖是什么时候起开始被宋江架空的……
References
Wickham, Hadley. 2017. Stringr: Simple, Consistent Wrappers for Common String Operations. https://CRAN.R-project.org/package=stringr.