第2章 数据
数据!数据!数据!没有泥的话我没法做出砖。—夏洛克·福尔摩斯
要是你的数据烂,不管啥统计程序都没救。— Berton Gunter, April 2005
在第1章里,我们学会了用R进行常规的数学运算和统计计算,并且做出了三张图:大气二氧化碳浓度时间序列,降水的季节变化图,北京的 PM2.5 日变化图。好像已经把R语言学完了。只是,总不能每次都把数据一个一个敲到代码里吧,也不能只使用R自带的数据自娱自乐吧。要是处理你自己文件里的大量数据呢?本篇就解决这个问题。
本书里我们会使用示例数据,方便你跟我们同步操作。示例数据文件可以请R来自动生成。运行下面这两行命令:
dir.create('c:/r4r')
write.csv(as.data.frame(t(matrix(
co2, 12, dimnames = list(
month.abb, unique(floor(time(co2))))))),
file = 'c:/r4r/co2.csv')将来我们会解释这两条代码的含义,现在你大可略去,只管去c盘找到一个名叫r4r文件夹,里面有个名叫co2.csv的文件。这就是我们做示范的示例数据文件,你就当作是从我们的光盘上拷贝过来的吧。请在学习本书的过程中保留“c:/r4r”这个文件夹,我们在后续章节所做的示范都要用到它。
请用Excel或记事本打开co2.csv这个文件。这是个数据表,内容是1959年1月到1997年12月夏威夷Mauna Loa观测站的大气二氧化碳浓度,以年份为行,以月份为列。不要做任何修改,我们现在假定这是你即将处理的数据文件,看看如何对其中的数据进行操作。
2.1 输入:读取文件
读取文件,就是让R把数据读进R的脑子里。
如果你喜欢拷贝粘贴的方式,那么可以用 Excel 打开数据文件 co2.csv ,用鼠标选中全部数据区(ctrl+a),拷贝,然后在 R 中用下面的代码读取剪切板里的数据(试一下“tab小助理”。以后每个长命令都用一下,养成习惯):
mydata1 <- read.table(file = "clipboard", header = TRUE)这条指令的含义是:读取剪切板里的数据,保存到mydata1这个数据框变量里。header = TRUE 翻译过来就是“文件头是真有啊“,意思是数据表的第一行是列名称。
这时,注意观察RStudio的 右上窗,出现了 mydata1 的信息。鼠标单击可以查看内容,也可以用输入代码并运行:
mydata1## X Jan Feb Mar Apr May Jun Jul
## 1 1959 315.42 316.31 316.50 317.56 318.13 318.00 316.39
## 2 1960 316.27 316.81 317.42 318.87 319.87 319.43 318.01
## 3 1961 316.73 317.54 318.38 319.31 320.42 319.61 318.42
## 4 1962 317.78 318.40 319.53 320.42 320.85 320.45 319.45
## 5 1963 318.58 318.92 319.70 321.22 322.08 321.31 319.58
## 6 1964 319.41 320.07 320.74 321.40 322.06 321.73 320.27
## ......
## 38 1996 362.09 363.29 364.06 364.76 365.45 365.01 363.70
## 39 1997 363.23 364.06 364.61 366.40 366.84 365.68 364.52好了,读取数据就是这么简单。如果这已经满足你的需求,那么就可以跳至第2.2节,进行后续操作了。不过,我们建议你耐心把本节读完。因为,用拷贝粘贴的方式读取数据,优点是简单灵活易上手,适合临时用一下;缺点是重复性差,下回你可能忘了上次拷贝的是哪个区域的数据,这不是 R 的做事风格。更多情况下,我们要告诉R,数据文件保存在哪里,只需把上面命令的剪切板clipboard换成数据文件的路径即可。下面我们详细介绍这种方法。
不习惯命令行的用户,可以通过下面的指令获取这个文件的路径(请在敲入时练习一下前面说过的“箭头快捷键“和“tab小助理”):
myfile1 <- file.choose()在弹出的窗口中选择文件c盘下r4r文件夹里的co2.csv。
好了,现在我们看看myfile1的值是什么。在RStudio运行:
myfile1## [1] "c:/r4r/co2.csv"是刚才选取文件的路径。这是获取路径的方法之一,比较符合很多人喜欢鼠标选择文件的习惯,但比较麻烦,每次使用这个代码时都得点一次。一般来说,我们存放数据的路径是固定不变的,所以更常用的方法,是在代码里直接敲入文件路径:
myfile2 <- "c:/r4r/co2.csv"
myfile2## [1] "c:/r4r/co2.csv"跟鼠标选取文件的结果完全相同。
注意:
- 路径的名称前后要用引号(单双都行,但要成对儿),表示这是一个字符串。
- 文件路径中上下级文件夹之间的斜线必须是斜线(
/)而不是反斜线(\), Windows用户一定要注意!其中的道理我们暂不深究。
myfile2里存储的文件路径,并不是文件内容。R现在知道文件在哪里,却不知道里面是什么内容。现在,我们让 R 读取文件的内容。
mydata2 <- read.table(file = myfile2,
header = TRUE, sep = ",")
mydata2sep参数表示数据列的分隔符,这里设置为逗号,表示读取逗号分隔的数据。
你也许会说,read.table() 括号里那么多东西,用起来也太复杂了吧?怎么记得住?对,谁都记不住,现在我们有请助理团的第二位成员隆重登场!只需要把光标放到代码read.table的任何一个字符处,按键盘的F1键,RStudio此时会在右下面板显示帮助信息,有详细的解释和实例。好好读读帮助吧,以后你会发现,F1小助理是仅次于tab的常用操作。除了tab小助理和F1小助理外,以后我们会介绍更多的小助理跟你见面。
小贴士 2.1 R菜鸟入门三大法宝
为了省事儿,我们可以用read.table()的瘦身简化版read.csv()函数,用来专门读取逗号分隔的.csv文件:
mydata2 <- read.csv(file = myfile2)跟上一条指令的效果完全相同。到此为止,数据文件中的数据就被R读进了他的脑子里。mydata1和mydata2这种二维表格数据,叫做“数据框”。
你可能会觉得麻烦,怎么在Excel里双击一下就搞定的事,在R里边却这么麻烦?是的,R对数据的读入并非“傻瓜”操作,也许在读数据上R比Excel麻烦10倍,但只要读进去了,后面会省事百倍千倍。而且,如果需要读入千百个数据文件,那么配合第5章的循环语句可以轻松搞定,而不必双击千百次。相信我们,磨刀不误砍柴工。
其实,上面的过程是一套分解动作,让我们容易理解读取数据的过程。实际应用时,只需一行代码:
mydata2 <- read.csv(file = "c:/r4r/co2.csv")write.csv()函数,跟read.csv()有什么关系?既然read.csv()是read.table()的瘦身版,那么会不会有个write.table()函数呢?要弄清楚这些问题,请试试你的三大法宝。
在RStudio中,像ctrl+shift+n、tab和F1这样的快捷键操作还有很多。从RStudio菜单栏选择Tools – Keyboard Shortcuts Help,或者直接按alt+shift+k键,就会弹出一本快捷键魔法书。
2.2 计算:数据处理和作图
R把数据读入脑子后,就可以开始干活儿了。
我们先让R对数据画个图,看起来更直观(图2.1):
plot(mydata2)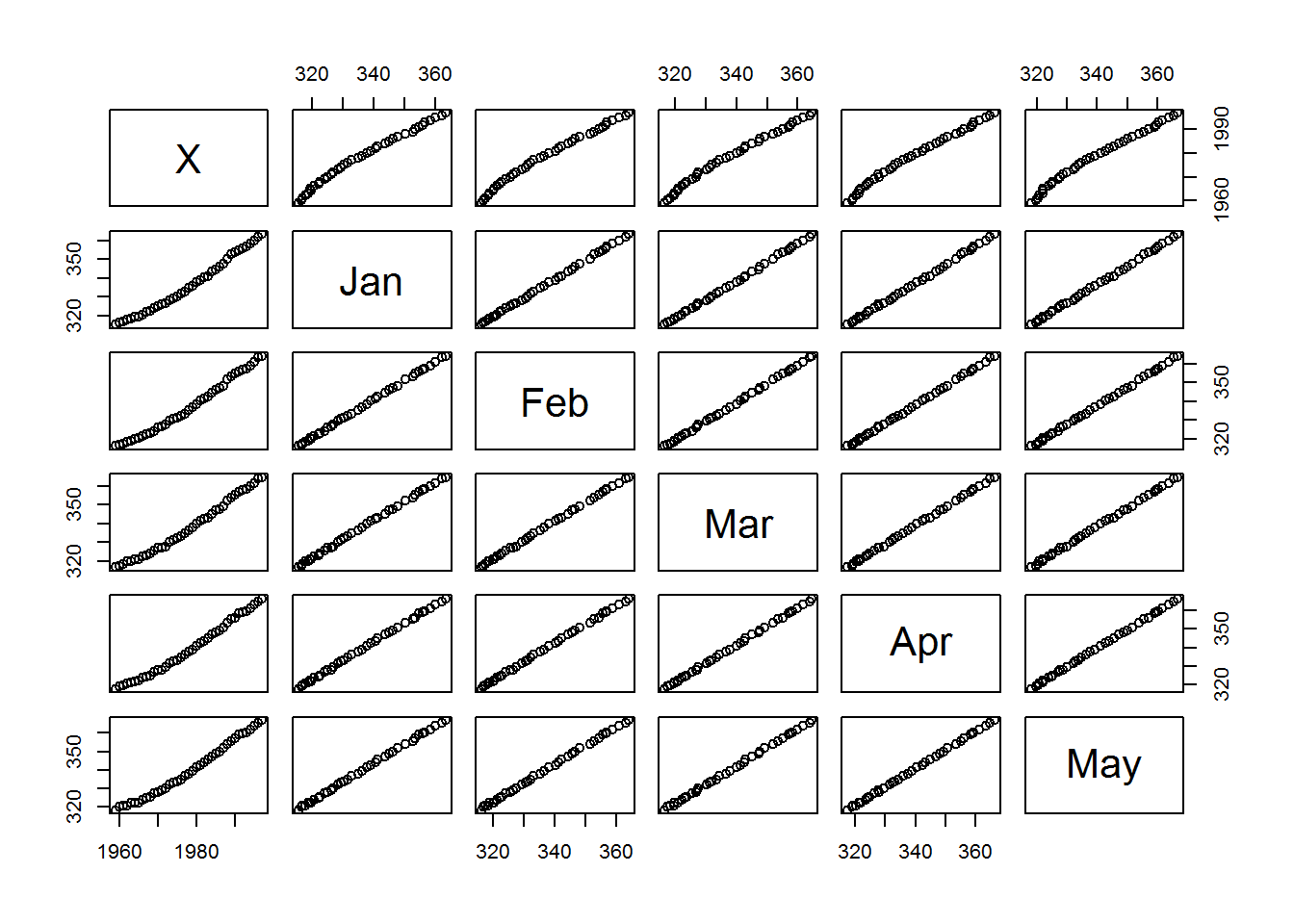
图 2.1: 多张小图一次完成(局部展示).
Bingo!多张小图一次完成!这就是事半功倍的效果。
你想多懒就多懒,并不耽误高效率。— Kevin Murphy, September 2003
这是任意两列的散点图。画的小图表示的是什么呢?比如从上数第2行第4列的小图,跟它排在同一行的文字是左边的Jan,这是小图的纵坐标标签;跟小图排在同一列的文字是下方的Mar,这是小图的横坐标标签。所以这个小图展示的是以3月的二氧化碳浓度x,1月份的二氧化碳浓度为y的散点图。其他小图可以类推。那么,第1列小图,展示的就是各月二氧化碳浓度的逐年变化。
这么复杂的图,简单一条指令就轻松做出来了。追求高效人士的利器!
我们一般在读入数据文件后的第一件事就是plot()一下,对数据有个整体的感觉。第二件事,一般是用summary()看看这个文件的总结报告,这个函数我们在第1章已经打过照面了:
summary(mydata2)## X Jan Feb
## Min. :1959 Min. :315.4 Min. :316.3
## 1st Qu.:1968 1st Qu.:323.1 1st Qu.:323.6
## Median :1978 Median :334.8 Median :335.2
## Mean :1978 Mean :336.4 Mean :337.2
## 3rd Qu.:1988 3rd Qu.:349.0 3rd Qu.:349.9
## Max. :1997 Max. :363.2 Max. :364.1
## Mar Apr May
## Min. :316.5 Min. :317.6 Min. :318.1
## 1st Qu.:324.6 1st Qu.:325.7 1st Qu.:326.3
## Median :336.5 Median :337.6 Median :337.8
## Mean :338.1 Mean :339.3 Mean :339.9
## 3rd Qu.:350.6 3rd Qu.:352.1 3rd Qu.:352.9
## Max. :364.6 Max. :366.4 Max. :366.8
## Jun Jul Aug
## Min. :318.0 Min. :316.4 Min. :314.6
## 1st Qu.:325.9 1st Qu.:324.9 1st Qu.:322.7
## Median :337.7 Median :336.4 Median :334.5
## Mean :339.3 Mean :337.9 Mean :336.0
## 3rd Qu.:352.3 3rd Qu.:350.8 3rd Qu.:349.1
## Max. :365.7 Max. :364.5 Max. :362.6
## Sep Oct Nov
## Min. :313.7 Min. :313.2 Min. :314.7
## 1st Qu.:321.2 1st Qu.:320.9 1st Qu.:321.9
## Median :332.6 Median :332.4 Median :333.8
## Mean :334.2 Mean :334.2 Mean :335.5
## 3rd Qu.:347.4 3rd Qu.:347.4 3rd Qu.:348.8
## Max. :360.2 Max. :360.8 Max. :362.5
## Dec
## Min. :315.4
## 1st Qu.:323.3
## Median :334.8
## Mean :336.7
## 3rd Qu.:350.0
## Max. :364.3得到的是每一列数据(也就是各年各月二氧化碳浓度)的最大值、最小值、中位数、平均值函数,顺便还附送了四分位数(1st Qu., 3rd Qu.)。什么是四分位数?试试猎狗。
放狗去搜。— 谢益辉13
如果我们想看看数据框里某个指定值,比如1995年9月二氧化碳的浓度,该怎么选取单元格呢?你还记得上一节我们是如何选取 4 月的降水量吗?x[4]。类似地,1995年是第37行,9月是第10列,所以:
mydata2[37, 10]## [1] 358.11要选取多个行呢?若你还记得用c()生成一个向量,那就好办了,比如选取第10列的全部偶数行:
mydata2[c(2,4,6,8,10,12,14,16,18,20,
22,24,26,28,30,32,34,36,38), 10]## [1] 314.00 316.11 316.54 318.48 320.18 322.93 324.68 327.27
## [9] 329.14 332.60 335.72 337.81 340.90 344.68 348.55 350.82
## [17] 352.94 355.84 359.51行数太多,逐个敲起来太麻烦了吧,高效人士的办法是用seq()函数生成个数列:
mydata2[seq(from = 2, to = 39, by = 2), 10]## [1] 314.00 316.11 316.54 318.48 320.18 322.93 324.68 327.27
## [9] 329.14 332.60 335.72 337.81 340.90 344.68 348.55 350.82
## [17] 352.94 355.84 359.51seq(from = 2, to = 39, by = 2) 表示以 2 为起点,39 为终点,间隔(即步长)为 2 生成一个数列。比如步长是1的话,就用seq(from = 2, to = 39, by = 1),等同于2:39:
mydata2[2:39, 10]## [1] 314.00 314.83 316.11 316.05 316.54 317.66 318.48 319.10
## [9] 320.18 322.22 322.93 323.20 324.68 327.35 327.27 328.40
## [17] 329.14 331.42 332.60 333.75 335.72 336.52 337.81 339.69
## [25] 340.90 342.92 344.68 346.27 348.55 349.64 350.82 352.05
## [33] 352.94 353.67 355.84 358.11 359.51 360.24如果是选取整行或整列的话, 为了省事儿,可以空出来相应位置:
mydata2[, 10] # 第10列全部。## [1] 313.68 314.00 314.83 316.11 316.05 316.54 317.66 318.48
## [9] 319.10 320.18 322.22 322.93 323.20 324.68 327.35 327.27
## [17] 328.40 329.14 331.42 332.60 333.75 335.72 336.52 337.81
## [25] 339.69 340.90 342.92 344.68 346.27 348.55 349.64 350.82
## [33] 352.05 352.94 353.67 355.84 358.11 359.51 360.24mydata2[37, ] # 第37行全部。## X Jan Feb Mar Apr May Jun Jul
## 37 1995 359.98 361.03 361.66 363.48 363.82 363.3 361.94
## Aug Sep Oct Nov Dec
## 37 359.5 358.11 357.8 359.61 360.74如果列数太多,总不能老去数第几列吧?别急,也可以用行或列名称来替代列数:
mydata2[, 'Sep']## [1] 313.68 314.00 314.83 316.11 316.05 316.54 317.66 318.48
## [9] 319.10 320.18 322.22 322.93 323.20 324.68 327.35 327.27
## [17] 328.40 329.14 331.42 332.60 333.75 335.72 336.52 337.81
## [25] 339.69 340.90 342.92 344.68 346.27 348.55 349.64 350.82
## [33] 352.05 352.94 353.67 355.84 358.11 359.51 360.24或者用美元符号后面跟着列的名称:
mydata2$Sep## [1] 313.68 314.00 314.83 316.11 316.05 316.54 317.66 318.48
## [9] 319.10 320.18 322.22 322.93 323.20 324.68 327.35 327.27
## [17] 328.40 329.14 331.42 332.60 333.75 335.72 336.52 337.81
## [25] 339.69 340.90 342.92 344.68 346.27 348.55 349.64 350.82
## [33] 352.05 352.94 353.67 355.84 358.11 359.51 360.24列名称都有哪些呢?其实在输入$符号后,RStudio就立刻贴心地把所有列名称列出来了,供我们选择。如果没有出现,请咨询tab小助理。除此之外,用names()函数或colnames()函数可以查看列名称:
names(mydata2) # 或 colnames(mydata2)## [1] "X" "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug"
## [10] "Sep" "Oct" "Nov" "Dec"第一列在原始文件中没有名字,所以R自动起了个名字叫做“X”。我们可以把它的列名称改为“year”:
names(mydata2)[1] <- 'year'
names(mydata2)## [1] "year" "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul"
## [9] "Aug" "Sep" "Oct" "Nov" "Dec"类似的,用rownames()函数可以查看行名称。由于我们并没有给各行起名字,R默认按数字顺序命名。我们可以将年份列作为行名称:
rownames(mydata2)## [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11"
## [12] "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22"
## [23] "23" "24" "25" "26" "27" "28" "29" "30" "31" "32" "33"
## [34] "34" "35" "36" "37" "38" "39"rownames(mydata2) <- mydata2$year
rownames(mydata2)## [1] "1959" "1960" "1961" "1962" "1963" "1964" "1965" "1966"
## [9] "1967" "1968" "1969" "1970" "1971" "1972" "1973" "1974"
## [17] "1975" "1976" "1977" "1978" "1979" "1980" "1981" "1982"
## [25] "1983" "1984" "1985" "1986" "1987" "1988" "1989" "1990"
## [33] "1991" "1992" "1993" "1994" "1995" "1996" "1997"这样,如果要查看1995年9月的数据,就不用再数第几行第几列了,用行名称和列名称更方便:
mydata2['1995', 'Sep']## [1] 358.11这对于处理大型的表格尤其方便,省得瞪着眼睛去数数寻找单元格了,很大程度上减少了对视力的伤害。
任何一行或一列,都可以作为向量来计算。我们仿照上一章介绍的向量计算方法,来算一下1995年全年二氧化碳的平均浓度,只要对该行的第2到13列求平均:
sum(mydata2['1995', 2:13]) / 12## [1] 360.9142如果求1996年比1995年二氧化碳浓度增加了多少,可以料想,只需把两行的平均值相减:
sum(mydata2['1996', 2:13]) / 12 -
sum(mydata2['1995', 2:13]) / 12## [1] 1.7725那么,1996年每个月比1995年同比增加了多少二氧化碳?
mydata2['1996', ] - mydata2['1995', ]## year Jan Feb Mar Apr May Jun Jul Aug Sep Oct
## 1996 1 2.11 2.26 2.4 1.28 1.63 1.71 1.76 2.04 1.4 1.85
## Nov Dec
## 1996 1.19 1.64这里我们可以体会向量计算的特点,是逐个对应相减的。
现在,你可以试着对任意一行或一列来做向量计算了。
整行或整列的计算,在R中有更方便的方法,可以这样:
colMeans(mydata2[, 2:13]) # 排除掉第一列后,对整列求平均## Jan Feb Mar Apr May Jun
## 336.4308 337.2033 338.0546 339.2944 339.8821 339.3282
## Jul Aug Sep Oct Nov Dec
## 337.9164 335.9579 334.2428 334.1692 335.4679 336.6946每年和每月的平均值一下就算出来了。类似的函数还有整行求和rowSum()和整列求和colSum()。函数名很好记,就是在原来函数前面加个row或col,并且注意大小写。
下面,我们对整行求平均值,并且把结果作为一列添加到mydata2中,列名称叫做mean:
mydata2$mean <- rowMeans(mydata2[, 2:13])如果不是求和或求平均值,而是求其他函数值,比如中位数、最大值、最小值呢?难道也是在原函数名前边添个row或者col就行了吗?呃,理论上当然是可以做到的(见第9章),但实际上没那个必要,因为那样就需要太多的新函数。我们可以用功能更强大的apply()函数:
mydata2$median <- apply(X = mydata2[, 2:13],
FUN = median, MARGIN = 1)这条代码,表示计算对象是mydata2[, 2:13]这个数据框,按行操作(MARGIN = 1),操作的函数是求中位数median。如果把median换成sum或mean,那么就跟rowSums()和rowMeans()的效果完全一样了。想了解apply()函数更多详细情况,请咨询F1小助理。
现在,我们可以用上一章认识的各种数学函数,对这个表格进行随便折腾了。
任意相邻年份某个月的二氧化碳浓度增量,也就是相邻两行的差,可以用diff()函数:
diff(mydata2$Sep)Example 2.2 请解释下面代码的含义,猜猜计算出来的结果是什么,再运行,看看跟你猜的是否一致。
apply(X = mydata2, FUN = diff, MARGIN = 2)
上面我们演示了如何让R读取一个数据文件,并简单分析和作图。从此以后,你就可以依葫芦画瓢来处理真正属于你自己的数据了!
回过头来看,我们上面处理的是表格数据。如果要处理其他格式的数据文件,尽管用我们前面介绍的鼠标选定拷贝到剪贴板的方法也可以达到目的,但是我们仍然建议你用Excel或别的软件将它保存或导出为.csv格式,方便R读取和进一步处理,这是首选方案。并且,我们建议你以后把所有数据都尽量从一开始就保存为 .csv格式,因为它就像全世界语言里的英语,到哪里都通用,几乎任何软件都能打开。如果这仍然满足不了你的需求,那么
请F1小助理搬出
read.table()和scan()函数的帮助文件;请阅读《R数据的导入和导出》这本书,来自开源社区,网上免费获取14;
如果经常处理Excel的xls或xlsx文件,请使用R相关的扩展包。这个方法我们会在第9章介绍。
R说明文档的水平已经远高于开源软件的平均水平了,甚至高过商业软件(特别是SPSS,老是摆出一张臭脸,说“如果你不懂输出的东西是什么含义,那么点击帮助按钮,我们会弹出5行你仍然不会弄懂的火星语。”)
— Peter Dalgaard, April 2002
2.3 输出:保存文件
数据文件的保存比读取要简单多了,用write.csv()函数即可。下面的语句把mydata2这个数据保存到c:/r4r文件夹下面,文件命名为“mydata2.csv”。
write.csv(mydata2, file = 'c:/r4r/mydata2.csv')现在我们可以解释本章开头两条代码的含义了:我们先用dir.create()函数在你电脑里创建了个文件夹,然后用write.csv()函数将一个名为co2的数据经过一系列格式转换后存成了co2.csv文件。
那么co2这个数据最初是怎么跑到我们的电脑里的?是R安装时捆绑自带的。我们可以运行
data()就可以看到R自带的很多数据文件。这些文件可以在学习R的过程里用来做各种测试。
在后面的章节中,如无例外,我们都使用R自带的数据做示例,省却读入数据的步骤。当然,如果想练习数据的读入,那么可以用本章开头的方法,把R自带数据存成数据文件,然后装作自己的文件从头操作。
今天的活儿干完了。我们关闭RStudio,收工。RStudio会弹出一个窗口,问你两件事(图2.2):
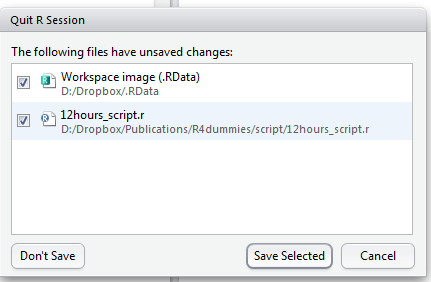
图 2.2: RStudio退出前保存.
你要不要把工作区存到一个.RData文件里?翻译过来就是:“主人,你要不要我把今天算出来这些数据记在我脑子里,就是右上面板工作区Environment标签下列出的里那些东西,下回打开我的时候直接就能用这些数据?” 保不保存随你心意。我们一般选择不保存,让RStudio把数据忘得一干二净,下回打开时右上方的窗口是空的,只需重新读入数据和计算就行了,反正原始数据在,而数据的处理方法都在代码里。
你要不要保存r代码?也就是左上方窗口这些东东?当然保存了。
现在,才算是真正收工了。
| 操作 | 提示 |
|---|---|
| 设定数据文件路径 | 路径里不要空格,不要中文,用斜线分隔,file.choose() |
| 读取数据 | read.table(),read.csv() |
| 保存文件 | write.csv() |
| 选取单元格 | x[2, 3],x[2, ],x[, 3],x$Sep,x[‘1995’, ‘Sep’] |
| 快速掌握数据 | plot(),summary() |
| 行列名称 | rownames(),colnames(),names(), |
| 行列计算 | rowMeans(),colMeans(),rowSum(),colSum(), apply() |
2.4 课外活动:有R伴我走天涯
R不仅可以安装在本地,还可以从网络访问。在你的手机或电脑里打开浏览器,访问下面介绍的网站,就可以使用R语言了。
我们先来试试Ideone15。打开这个网站后,输入图2.3上方窗口里的代码,点击Run!按钮运行,窗口下面就立刻显示运算结果。
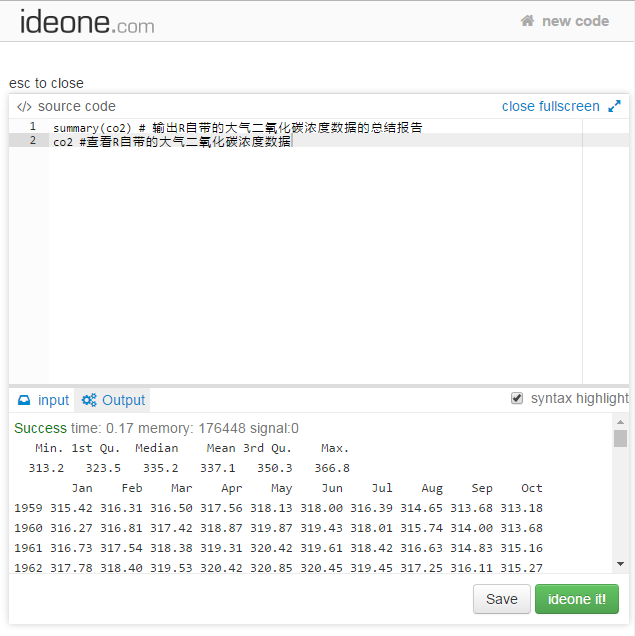
图 2.3: R在线调试网站Ideone.
Ideone可以让我们用浏览器来进行R编程和调试,非常方便。喜欢的话,可以注册个免费账号,这样就可以将一些代码保存在自己名下,方便以后调用。它还支持把代码嵌入到网页里,以便分享。
由于输入输出接口的限制,Ideone里的R语言不能读入外部数据,也不能实现作图。另一个网站RWeb16则解决了这些问题,支持从本地或网络上导入数据,并可以输出图片。
如果你有自己的服务器,那么还可以用RStudio的服务器版来搭建自己专属的R网站,你的地盘你做主。
有了这些在线的R网站,随时随处都可以免费使用R,没有电脑就用手机。有R伴我走天涯,走到哪里都不怕。
统计之都 R 语言论坛:https://d.cosx.org/t/r↩
益辉的中文博客:https://yihui.name/cn/↩
R数据的导入和导出:http://pem.freeshell.org/math/R_data_import_export_zh.pdf↩
Ideone:http://ideone.com↩